Play Framework 2.9.0 に送ったPull Request
そろそろPlay Framework 2.9.0が出そうですね。ということで自分の送ったPull Requestをまとめてみました。
大きいところだとTwirlのScala 3対応ですね。いい感じにエラーメッセージ出すのにdottyとかsbtまで調べることになって沼でしたがたぶんなんとかなりました。
playframework/playframework
- Let the Java Form validator use the locale selected by Play's i18n. #11736 https://github.com/playframework/playframework/pull/11736
- Update caffeine, jcache to 3.0.1 #11444 https://github.com/playframework/playframework/pull/11444
playframework/twirl
- Added support for switching the default "import" between Scala 2 and Scala 3 #613 https://github.com/playframework/twirl/pull/613
- Handle an exception from scalameta when parsing template args fail #512 https://github.com/playframework/twirl/pull/512
- Call toIndexedSeq explicitly to reduce warnings #487 https://github.com/playframework/twirl/pull/487
- Add a testcase for By-name parameters #485 https://github.com/playframework/twirl/pull/485
- CI with GitHub Actions (using playframework/.github) #483 https://github.com/playframework/twirl/pull/483
- Add syntax related fixes for Scala3 cross build #479 https://github.com/playframework/twirl/pull/479
- Update scalafmt to 3.3.1 #478 https://github.com/playframework/twirl/pull/478
- feat(scala3): WIP working on scala 3 cross compilation. #390. #461 https://github.com/playframework/twirl/pull/461
sbt/zinc
- Display error messages based on the transformed positions when source mapping is perfomed #1082 https://github.com/sbt/zinc/pull/1082
おまけ
今年もかぼちゃ育てたので見て

ハロウィンかぼちゃを育てる
ご近所さんにハロウィン用のかぼちゃを育てている人がいて、毎年ハロウィンになると家の前にかぼちゃで作ったジャック・オー・ランタンを並べている。真似してみた。
ポイント
育てる難易度はあまり高くない。食用かぼちゃと違ってハロウィン用の観賞用かぼちゃは味を気にする必要がない。見た目もきれいな形になるにこしたことはないけれど、いびつだとしてもそれがジャック・オー ・ランタンの味になるので気にすることはない。
難しいのは単純にかぼちゃが大きすぎて扱いづらいということ。できれば協力者が欲しい。
収穫時期はコントロールするのが難しいが、できるだけ遅いほうが良い。ハロウィンかぼちゃは水分が多く腐りやすいので、早すぎるとハロウィンまでに持たずに腐ってしまう。保存方法で工夫の余地はあるとはいえ、収穫して2ヶ月以上持たせるのは難しいようだ。
種購入と苗作り
種はデカかぼちゃとしてはメジャーな品種と思われるアトランティックジャイアントを購入した。ゴールデンウイーク直後に種を植えて発芽を待った。

種まきの時期は地域によっても違うが本来は4月くらいだろうか。私が住んでいるのは仙台で、やや涼しめの気候なので少し遅らせた。
育苗ポットに種をまいてから1週間から2週間程度で発芽した。ちなみにアトランティックジャイアントは食用かぼちゃに比べてこの時点ですでにでかい。
定植
6月、苗に本葉が出てきたところで畑への定植をした。これもやり方は食用かぼちゃと変わらない。
念のため、食用かぼちゃやスイカなど、ウリ科の交配してしまいそうな作物の隣ではない場所を選んだ。

水やりと追肥
その後水やりは適度にしたが、ほぼ放置状態で育てた。
花が咲いたタイミングで祖父が授粉作業をしたりしていたが、授粉していない花にも実が出来たりしたので必須ではなさそう。
実が出来たら形が良くなるように起こしてあげたりした。ただ無理にやるとつるが折れてしまうので無理にはやらないほうが良い。実を大きくするためにはどんどん追肥した方が良いが、あれよあれよという間に大きくなっていくかぼちゃを見て、大きすぎても困るのでしなかった。

収穫
実が十分に育つとやがて実につながる茎が白く変色してひび割れてくる。時期にもよるが、これ以上は腐ってしまいそうだと感じたら収穫する。

保存
保存が一番難しい。
ハロウィンかぼちゃは水分が多く、かぼちゃというよりは「瓜」という感じの実だ。それをハロウィンまで腐らせずに保管するには色々と工夫がいる。
まず、傷をつけないこと。それからよく乾かすこと。特にヘタの部分は水っぽいので収穫直後にドライヤーなどで乾かすこと。木工用ボンドで固める人もいるらしい。その後日陰で風通しの良いところに置いて保存する。
いろいろ策を講じても、ご近所さん曰わくだいたい2ヶ月以上保存するのは難しいようだ。保存に力を入れるよりは実ができる時期を調整したいところだが、天候に左右されるところもあると思うし良い方法を知らない。
夏ごろに出来たかぼちゃは腐らせてしまった。運良くハロウィン直前まで収穫を遅らせることができたかぼちゃもありランタン作りにはそれを使った。

運搬
ノリで始めたデカかぼちゃ作りだが、実際に現物が出来てしまうと運搬の問題に直面した。重さもあるが球体なので1人で抱えるのには難があり大きいものは複数人で運ぶしかない。運ぶときにはブルーシートなどに載せてシートの四隅を持って運んだりすると楽だった。
ランタン作り
ランタン作りは思っていたより簡単だった。食用かぼちゃと違ってさほど硬くないし、内部の空洞をそのまま利用するので、筋力に自信が無くても大丈夫。ただしかぼちゃが大きくて時間もかかるので多少は疲れる。
まずかぼちゃの底に直系20cmくらいの穴を開けて、そこからわたを掻き出す。次に顔を作ってあげる。ライトアップはご自由に。

飾る
できたランタンは家の前に置いた。日持ちは天気か良ければ一週間くらいはしそうだ。
夜になるとなめくじが来ることがあってそれはちょっと困っている。対策が必要そう。

まとめ
散歩してる人や子どもたちが面白がってくれているようだし、かぼちゃ作りも適度な難易度があって楽しい。来年もやろうと思う。ランタン作りの際に種もとっておいた。
ScalaMatsuri 2022でCats Effect 3の話をしました
純粋関数型スタイルのプログラミングは私はあまりやって来なかったんですが、たまには違ったことをやってみようかなと思って発表してみました。年末年始にTypelevelの技術スタックをいろいろ見ててhttp4sとかさわってみてたりしたんですが、その過程でCats Effect 3が気になった感じです。
やはり純粋関数型スタイル自体にはそんなに興味ないんですが、Cats Effectのランタイムは面白くて、それに乗っかるためのフレームワークとして純粋関数型スタイルが要求されるというのはそんなに悪くないなと思いました。あと資料作成や準備の過程でCats Effectの作者の方(Danielさん)のトークを何本かYouTubeで見たんてすが面白すぎる。全部面白い。
Scalaは人気のピーク(ピークと言うほどでもない)を越えてしまって少しコミュニティの熱量は下がってるのかなって気がしますね。とは言え個人的には他に乗り換えたい言語もなく、今やるならRustなんだろうけどRustでWebアプリとか作る気にはならないしなあ、みたいな微妙な気持ちです。まあしばらくはplayframeworkのほうをやっていきます。あとPHPとかですかね?(冗談じゃなくて今本業PHPなんです)
Play Frameworkの開発チームに入れてもらいました
Play FrameworkがLightbendの手から離れる という発表が昨年の10月にあったんですが、それをきっかけにやりとりして Play FrameworkのGitHub Team に入れてもらいました。 しばらく待ちの状態だったんですが、先週くらいから動き初めたところです。とりあえず当面はTravis CIからGitHub Actionsへの移行やScala3対応になるのかなと思います。
PlayはLightbendから離れる決定をしたあとからOpenCollectiveで寄付を募っています。 寄付してくれてる方々を見ると日本の方も多いですね。ありがとうございます。 mkurzさんからも感謝のメッセージをいただいてます。引き続きご支援お願いします 🙏
// mkurzさんは私が何か働きかけたように思ってそうだが何もしていない Also, a high proportion of the current Play backers on Open Collective are Japanese, so it seems you reached out to the Japanese community already? If so, and if you have a mailing list or similar set up, would you mind to say thank you to them from me and the other contributors ;)
最近のタグジャンプ事情を調べた
テキストエディタのタグジャンプ機能、最近はどんな感じなのかなあと思って調べていました。 結論としては10年前とあまり変わっていないみたい。というか新しいツールが出てきていなくて、進化が止まっている印象。
ctags
exuberant-ctagsは2009年のリリース以降開発が止まっていて、代わりにuniversal-ctagsというもののメンテナンスが続いていました。 exuberant-ctagsはMacではパッチ当てないとビルドできなかったし、もうかなり厳しそう。でもまだ使っている人多そう。
GNU Global
GNU Globalはそんなにアクティブじゃないけどメンテナンスはされていて、新しいバージョンもぽつぽつと出てました。 Macで最新リリースをビルドして見たらconfigureが通らなかったんだけど、リポジトリの方を見たらそのためのパッチは取り込まれていました。 まだ使えそうではある。
その他
さすがにもっと改良されたやつとか出てきてるだろうと思って調べたけど全然ない。タグファイル作ってタグジャンプする時代は終わったんですね。 最近だとLSPみたいなIDE機能を使うかag/ripgrepとかを使いこなすというのが主流っぽい印象を受けました。
コード書く上ではLSPやIDEが強いけど、コードを読むだけだったらタグジャンプの方が手軽で便利に感じる時もあるので、もうちょっとあってもいい気がするんですけどね。なんかいいのあったら教えてください!
Emacs + Metals + lsp-mode でScalaを書く
最近重たい処理走らせてる時とかにIntelliJが遅くてつらかったのでEmacsでもある程度コード読んだり書けたり出来るようにしました。 最近はLSPが人気あるようでEmacsでもlsp-modeというのが結構使われているみたい。Scalaの場合はLSPとしてMetalsを使うことになります。
設定
- lsp-modeが入っていればとりあえずOK
- flycheckを入れてコンパイルエラーの表示が出来るようにしましょう
- lsp-uiを入れてなんかUIからポチポチ出来るようにしましょう
- companyをコード補完機能に使いましょう
(use-package flycheck :init (global-flycheck-mode)) (use-package lsp-mode :hook (lsp-mode . lsp-lens-mode) (scala-mode . lsp) :config (setq lsp-prefer-flymake nil)) (use-package lsp-ui) (use-package company :hook (scala-mode . company-mode) :config (setq lsp-completion-provider :capf) (setq company-minimum-prefix-length 1))
そんなにガリガリ設定書かなくても割といい感じになるのがすごい。
使い方
- インストールはMetalsのドキュメントでどうぞ。
M-.,M-,で定義元にジャンプしたり戻ったりできる。- キーバインドの一覧は https://emacs-lsp.github.io/lsp-mode/page/keybindings/
- 一覧に乗ってないけど
s-l g eでエラー一覧表示ができた。ドキュメント更新のpull req送った方良いのかな?
トラブルシューティング
デバッグはとりあえず *lsp-log* バッファを見てみると何か分かる。Metalsの場合は .metals/metals.log でも良し。
必殺再起動は M-x lsp-restart-workspace。
ハマったとこ
補完がうまく行かないなあ、Any型と判定されるなあとか思ってたんだけど、monorepo的なリポジトリでworkspaceのルートが誤判定されてちゃんとプロジェクトが読み込まれていないのが原因でした。M-x lsp-workspace-folder-add で設定したら補完ができるようになりました。
あと大きなプロジェクトで遅くなるけどファイルをウォッチするか?遅くなるけど?と聞かれた時に読み込まないようにしたら補完が効きませんでした。ウォッチしないとダメなのかな。とりあえずウォッチすることにして、遅くなってから考えることにしました。
制限
今のところ機能的にここが限界だろうなあというのが2つ。
感想
コード読んだり、調査だったり、ちょっとした修正には十分な機能なので嬉しい。まあガッツリコード書くときはIntelliJだけどそれ以外を軽い環境でカバー出来るのは良いですね。
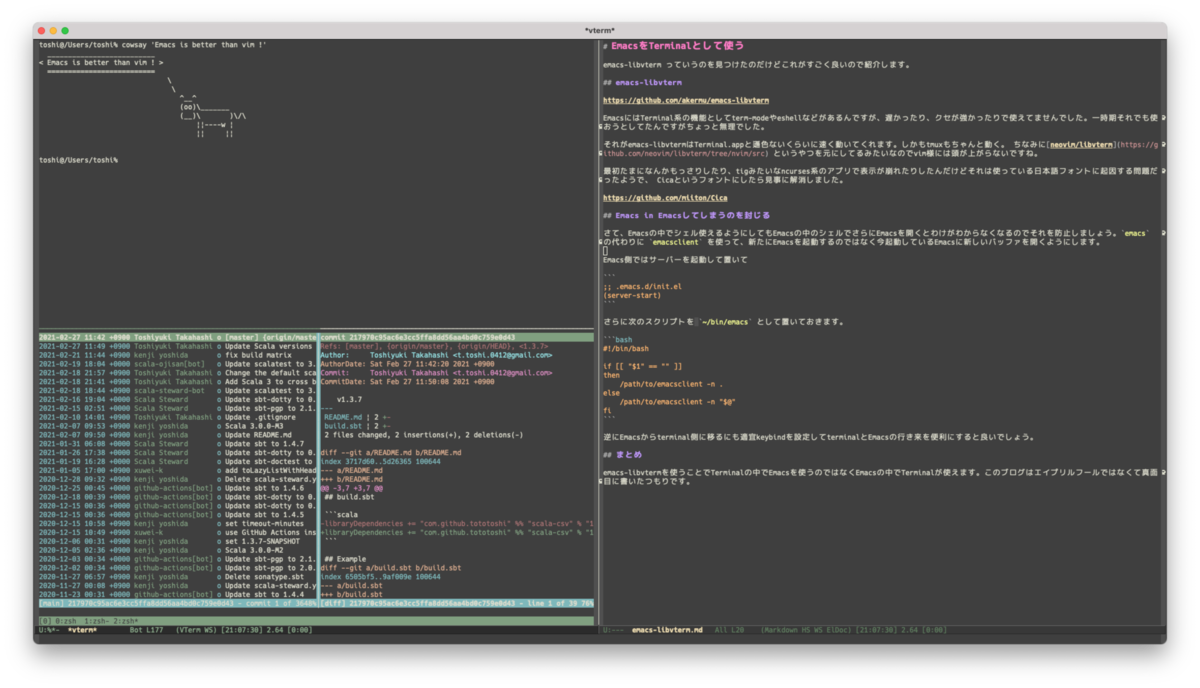
EmacsをTerminalとして使う
emacs-libvterm っていうのを見つけたのだけどこれがすごく良いので紹介します。
emacs-libvterm
https://github.com/akermu/emacs-libvterm
EmacsにはTerminal系の機能としてterm-modeやeshellなどがあるんですが、遅かったり、クセが強かったりで使えてませんでした。一時期それでも使おうとしてたんですがちょっと無理でした。
それがemacs-libvtermはTerminal.appと遜色ないくらいに速く動いてくれます。しかもtmuxもちゃんと動く。 ちなみにneovim/libvterm というやつを元にしてるみたいなのでvim様には頭が上がらないですね。

試し始めはたまになんかもっさりしたり、tigみたいなncurses系のアプリで表示が崩れたりしたんだけどそれは使っている日本語フォントに起因する問題だったようで、 Cicaというフォントにしたら見事に解消しました。
https://github.com/miiton/Cica
Emacs in Emacsしてしまうのを封じる
さて、Emacsの中でシェル使えるようにしてもEmacsの中のシェルでさらにEmacsを開くとわけがわからなくなるのでそれを防止しましょう。emacs の代わりに emacsclient を使って、新たにEmacsを起動するのではなく今起動しているEmacsに新しいバッファを開くようにします。
Emacs側ではサーバーを起動して置いて
;; .emacs.d/init.el (server-start)
さらに次のスクリプトを ~/bin/emacs として置いておきます。
#!/bin/bash if [[ "$1" == "" ]] then /path/to/emacsclient -n . else /path/to/emacsclient -n "$@" fi
逆にEmacsからterminal側に移るにも適宜keybindを設定してterminalとEmacsの行き来を便利にすると良いでしょう。
まとめ
emacs-libvtermを使うことでTerminalの中でEmacsを使うのではなくEmacsの中でTerminalが使えます。このブログはエイプリルフールではなくて真面目に書いたつもりです。